










 Claude
Claude
Ces dernières années, l’intelligence artificielle a profondément transformé le monde, notamment grâce aux IA génératives et les Large Language Models (LLM) qui se reposent sur l’architecture Transformer. Parmi ces modèles, ChatGPT et ses applications se sont imposés comme l’un des outils les plus populaires et les plus performants du marché, si bien que certaines entreprises veulent l’avoir dans leur activité.
Pour cela, OpenAI (les créateurs de ChatGPT) a créé l’API OpenAI, la solution IA idéal la plus utilisée pour créer des applications sur mesure basée sur l’IA, comme les chatbots, les assistants automatisés, la génération de contenu, l’analyse de données, l’automatisation métier et bien d’autres. Mais avant d’intégrer l’IA dans son entreprise, une question se pose naturellement : Quel est le coût de l’API OpenAI en 2026 ?
Or, les tarifs sont très difficiles à prévoir pour beaucoup d’entreprises et de développeurs à cause de son fonctionnement qui se repose sur des jetons ou des tokens qui varient selon les modèles. C’est pourquoi notre agence IA DigitalUnicorn vous donne ce guide complet sur le coût de l’API OpenAI, les jetons, les modèles disponibles et le calcul des coûts.
Tout savoir sur l’API OpenAI ?
Tout d’abord, avant entrer dans le coût, il essentiel de savoir ce qu’est l’API OpenAI et son fonctionnement. Notre agence d’application web DigitalUnicorn vous le présente :
OpenAI est une entreprise spécialisé dans la recherche, le développement et le déploiement de l’IA crée en 2015. Elle est, la créatrice du célèbre ChatGPT, une IA générative ou aussi un Large Language Model (LLM) qui est capable de répondre à toutes les questions, mais aussi de générer des images ou des vidéos avec le modèle DALL-E et Sora.
Qu’est-ce que l’API OpenAI ?
Dans ce contexte, l’API OpenAI est une interface de programmation d’application qui permet aux développeurs et aux entreprises d’intégrer des puissants modèles d’intelligence articielle d’OpenAI dans leurs propres applications, sites web, logiciels ou autres plateformes et outils.
De ce fait, grâce à cet API, il est possible de créer des applications sur mesure basée sur l’IA avec des fonctionnalités adaptées aux activités d’une entreprise, comme GPT, DALL·E, Whisper ou encore l’API Assistants, sans développer l’IA par soi-même. De ce fait, l’API OpenAI est une sorte de pont entre l’application de l’entreprise et les modèles d’OpenAI qui fonctionne grâce à l’envoi de requête.
Comment fonctionne l’API OpenAI ?
D’abord, l’API OpenAI sert alors à :
- Générer du texte (articles, email, script…) ;
- Résumer, améliorer et traduire du contenu ;
- Créer de l’image, de logo et de la vidéo ;
- Construire des chat bots intelligents ;
- Automatiser des tâches (analyse de données, support client…),
- Concevoir des assistants IA ;
- Transcrire l’audio en texte.
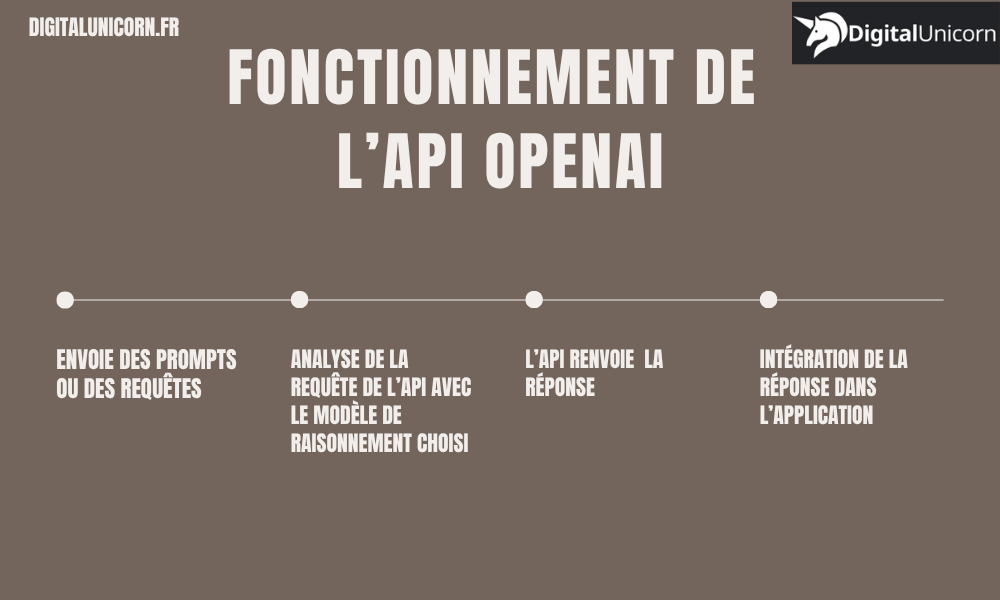
Ces différentes fonctionnalités peuvent être ajoutées à votre application via différents types de modèles complexes de raisonnement que vous choisissez en amont. De ce fait, voici comment l’API fonctionne :
- L’application envoie des prompts ou des requêtes (texte, données, instruction) ;
- L’API analyse la requête avec le modèle de raisonnement choisi (GPT-4, GPT-5, DALL-E, SORA, Whisper…) ;
- Elle renvoie la réponse sous forme de contenu généré : texte, image, vidéo, audio… ;
- Et la réponse peut être intégrée dans l’application via au chatbot, outil ou fonctionnalité interne, plateforme e-commerce, CRM et bien d’autres.
Profitez des crédits gratuits OpenAI et laissez DigitalUnicorn vous accompagner pour obtenir jusqu’à 20k€ de crédits supplémentaires afin de booster votre solution IA.
Comprendre la tarification de l’API OpenAI
Maintenant, que vous savez un peu plus sur l’API OpenAI, notre agence IA DigitalUnicorn vous aide à comprendre sa tarification qui se repose sur 3 piliers, dont le modèle utilisé, le nombre de jeton consommé et le type d’opération de son utilisation. De ce fait, plus le modèle est nombreux et puissant, puis son prix est élevé et vice-versa. Et chaque modèle possède son propre coût par 1000 jetons.
Qu’est-ce qu’un jeton et pourquoi est-il important ?
Un jeton représente une petite brique de texte que le modèle IA utilise pour mesurer la quantité de données qu’il traite. En d’autres termes, 1 jeton équivaut à un mot court et courant de 4 caractères en français. De ce fait, 100 jetons sont égaux à 400 caractères ou à peu près 75 mots et 750 mots pour 1000 jetons.
Ce concept est très essentiel parce que l’utilisation de l’API OpenAI est facturée au nombre de jetons. En effet, chaque requête consomme des jetons qui comprennent le texte d’entrée et le texte généré. Plus la demande est longue, plus la réponse est détaillée et plus le prix est élevé.
Par exemple, un prompt de 300 mots avec une réponse de 500 mots équivaut à 1000 jetons. Comprendre ce système vous permet de maîtriser les prix et éviter les imprévus.
Les différents modèles d’API OpenAI disponibles en 2026
En 2026, OpenAI propose plusieurs familles de modèles dont chacun a un prix et un usage spécifique :
GPT-4o (Omni) – Modèle polyvalent et multimodal
Le modèle Omni est spécialisé dans la compréhension de texte, d’image, de vidéo et d’audio, idéal pour les chatbots, le brainstorming et les assistants métiers. C’est un bon compromis entre performance et prix.
GPT-4.1 et GPT-4.5 – Modèle avancé pour les usages professionnels
GPT-4 a une meilleure précision dans la logique, la rédaction et les calculs. Il est aussi plus orienté vers le la créativité et le ton émotionnel, idéal pour le storytelling et le design communicationnel. Cependant, il est plus coûteux, utilisé dans les logiciels SaaS, les analyses complexes et la génération de rapport.
GPT-5-mini et GPT-5-light – Ultra optimisés pour le coût
Ses prix sont très abordables par 1000 jetons avec une vitesse et une efficacité optimale, idéal pour l’automatisation en masse et pour les starts-up. Il est spécialisé pour les tâches bien définies comme la classification, la reformulation simple, ou les réponses aux FAQ.
GPT-5, GPT-5.1 et GPT-5.1 thinking–modèle avancé
Ce sont les versions les plus récentes, mais GPT-5 est maintenant remplacé par GPT-5.1. Ce modèle est optimisé pour le codage complexe et les tâches agentiques nécessitant une logique de haut niveau. GPT-5.1 thinking est une variante de GPT-5.1 orienté pour le raisonnement avancé. Bien évidemment,
Modèles d’Embeddings
Ces modèles sont faits pour rechercher, classer, résumer ou indexer des données ou des informations avec des prix très faibles. Idéal pour créer des bases de connaissances, des moteurs de recherche internes, des RAG, etc.
Modèles Vision
Le modèle vision est spécialisé dans l’analyse images avec une facturation spécifique à la résolution et aux jetons générés.
Comment fonctionne la facturation au jeton ?
La facturation se repose sur l’utilisation du nombre de jetons et le prix du modèle. Le nombre de jetons prend en compte le prompt (ex : 400 mots = 500 jetons), la réponse (ex : 700 mots = 900 jetons), soit un total 1400 jetons. Le prix d’un modèle est déterminé par 1000 jetons.
Par exemple, le coût d’un modèle GPT-4o est de 0,0025$/1000 jetons pour le texte d’entrée et 0,015$ pour le texte de sortie. De ce fait, le prix total de cet exemple est de : (500j * 0,0025/1000) + (700j*0,01/1000) = 0,00825. Pour 1000 requête de ce genre, comptez alors 8,25$ sur GPT-4o. Pour un outil SaaS avec 20.000 requêtes/mois, ce prix est très abordable, soit environ 165,5 euros.
Tarifs détaillés des principaux modèles OpenAI pour 2026
Après avoir compris le système de tarification et sa méthode de calcul, notre agence mobile Paris DigitalUnicorn vous présente les frais détaillés des principaux modèles OpenAI en 2026 :
GPT-4o et GPT-4o Mini : Tarifs et spécificités
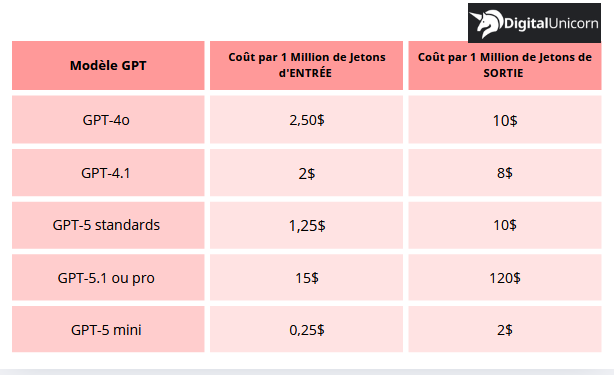
Le prix modèle GPT-4o est de 2,50$/1M jetons pour le texte d’entrée et 10$/1M jetons pour le texte de sortie. Ces frais indiquent que GPT-4o est très abordable, idéal pour les usages volumineux avec une technologie omni (multimodal : texte, vidéo, image, audio) et une performance acceptable. Il n’est pas donc conseillé pour le raisonnement avancé et les tâches complexes.
GPT-4.1 et GPT-4.1 Mini : Prix et cas d’usage
GPT-4.1 et GPT-4.1 Mini sont l’évolution de GPT-4o avec une meilleure compréhension, un traitement rapide et une fenêtre d’accès plus large, mais limité au texte. Ses frais sont inférieur à GPT-4o qui sont de 2$/1M pour l’entrée et de 8$/1M de jetons pour la sortie et pour le GPT mini, comptez 0,4$ pour l’entrée et 1,60$/1M de jetons pour la sortie.
C’est le modèle idéal pour les entreprises qui recherchent une forte logique, le codage et une compréhension de contexte long (ex : analyse de documents, assistants métiers) conçu pour les rédacteurs, les développeurs et autres.
GPT-5 et variantes : frais et spécialités
Les modèles GPT-5 et ses variantes sont les nouvelles versions et références d’OpenAI pour le raisonnement de haut niveau, et leur tarification est logiquement plus élevée que les modèles précédents (GPT-4 ou GPT-4o), mais tout en restant gérée par jeton. Voici les différents modèles de GPT-5 :
- GPT-5 standards: 1,25$/1M de jetons pour le coût d’entrée et 10$/1M de jetons pour le coût de sortie, idéal pour les tâches complexes générales, le raisonnement avancé et le codage ;
- GPT-5.1 ou pro: 15$/1M de jetons pour le coût d’entrée et 120$/1M de jetons pour la sortie, conçus les tâches critiques, raisonnement multi-étapes et agents sophistiqués, c’est le meilleur modèle ;
- GPT-5 mini: 0,25$/1M de jeton pour l’entrée et 2$/1M de jeton pour la sortie, u modèle très rapide pour le chat simple, la classification, et les automatisations de base.
Modèles de génération d’images (DALL-E 3) : Tarification
Le prix de DALL-E 3 (la dernière version) est facile à calculer. En effet, le coût dépend de la résolution de l’image, plus cette dernière est de qualité plus le prix est élevé. Voici quelques exemples :
- 1024 x 1024 Carré (Square) par image par image pour la qualité Haute Définition ;
- 1792 x 1024 Paysage (Landscape) par image par image pour le HD ;
- 1024 x 1792 Portrait (Portrait) par image par image pour le HD.
La tarification ne dépend pas des jetons, mais par image créée. Vous payez alors par image générée quelle que soit la complexité du prompt et sa longueur. Mais, si vous utilisez DALL-E 3 via ChatGPT, le prix est inclus dans l’abonnement mensuel. Le tarif ci-dessus ne s’applique qu’à l’API OpenAI.
Modèles d’embeddings, de modération et autres
Les modèles d’embeddings transforment le texte en longues séries de nombres (vecteurs) pour réaliser de la recherche sémantique (RAG, Récupération Augmentée de Génération) et la classification. Ils sont facturés au jeton d’entrée uniquement, car ils ne génèrent pas de texte en sortie. Il existe deux versions et voici ses frais :
- text-embedding-3-small0,02 $US/1M de jetons, idéaux pour les tests et les applications où la précision n’est pas prioritaire. Prix extrêmement bas ;
- text-embedding-3-large0,13 $US/1M de jetons, le modèle le plus performant qui offre la meilleure précision pour la recherche sémantique complexe sur de vastes bases de données.
Facteurs influençant le coût de votre utilisation de l’API OpenAI
À cause de la complexité des prix qui fonctionnent par jetons, il est assez difficile de prévoir le coût final. Notre agence DigitalUnicorn vous aide alors à comprendre les facteurs qui font varier votre facture pour mieux anticiper les dépenses et les imprévus. Les voici :
Taille de la fenêtre contextuelle (context window)
Chaque modèle d’OpenAI dispose d’une fenêtre contextuelle qu’il faut comprendre. Elle indique la quantité de texte (en jeton) qu’elle peut traiter à la fois. De ce fait, plus la fenêtre est volumineuse, plus le prompt inclut de données, plus le modèle doit analyser plus d’informations, plus le coût en jeton augmente.
Les modèles les plus récents comme GPT-4.1 ou GPT-5 peuvent gérer des textes très longs (jusqu’à plusieurs millions de jetons), mais les requêtes volumineuses impactent directement votre budget. De ce fait, limitez et optimisez la taille des textes fournis d’entrée pour réduire les dépenses au maximum.
Fréquence et volume d’appels
Le coût total de l’intégration API IA dépend directement du nombre d’appels d’API par minute et du volume de requête quotidien ou mensuel. De ce fait, les chatbots internes, les sites SaaS et les outils d’automatisation peuvent générer des millions d’appels par mois.
Même si le coût unitaire par jeton est très faible, l’accumulation de millions de prompt avec les résultats peuvent être élevée. De ce fait, regrouper les demandes et utiliser des mises en cache pour éviter des appels répétés.
Utilisation de modèles spécifiques (plus ou moins coûteux)
Le choix du modèle impacte directement le coût de l’intégration API. Il faut donc avoir un modèle bien adapté à ses besoins pour éviter des surplus de coûts inutiles, voici un petit résumé :
- Les modèles premium (GPT-5, GPT-5.1, GPT-4.1) : modèle premium cher, mais meilleur raisonnement, agentique et tâche complexe ;
- Les modèles intermédiaires (GPT-4o, GPT-4o-mini) = excellents compromis entre performance et coût.
- Les modèles économiques (GPT-3.5 Turbo, GPT-5-mini) = prix très abordables, mais limités.
Mise au point de modèles (fine-tuning)
Le fine-tuning consiste à entraîner un modèle spécifique sur vos propres données. Ce type de solution est très puissant et très pratique, mais il implique :
- Un coût d’entraînement initial (selon les jetons utilisés pour l’apprentissage),
- Un prix d’inférence parfois plus élevé que le modèle standard.
Le fine-tuning est recommandé si votre cas d’usage nécessite un comportement très spécifique ou si vos prompts doivent être trop longs à chaque utilisation.
Estimer le coût de vos projets avec l’API OpenAI
Maintenant, vous pouvez calculez précisément le coût de l’API Open AI selon vos besoins, votre budget et vos objectifs. Notre agence de développement informatique DigitalUnicorn vous donne quelques exemples.
Calculer le nombre de tokens utilisés
Le coût d’un projet d’intégration IA via API OpenAI peut être facilement calculé avec les jetons que vous devez maintenant comprendre. Pour cela :
- Estimez la longueur moyenne de chaque prompt ;
- Estimez la longueur moyenne de chaque réponse (vous pouvez les limiter) ;
- Convertissez le nombre de mots en jetons (750 mots équivalent à peu près à 1000 jetons) ;
- Multipliez-le par le nombre d’appels prévus de l’API (ex : 25.000 requêtes/mois).
Utiliser des calculateurs de coûts en ligne
Pour vous aider, il existe plusieurs outils en ligne calculateurs de coût de jeton que vous pouvez utiliser. Ils calculent automatiquement le nombre de jetons par texte (prompt et réponse), le coût total selon les modèles et même la comparaison à chaque modèle. Ces outils, comme, OpenAI tokenizer, Token calculateur tiers ou PricePerToken, vous permettent d’estimer rapidement vos futures factures.
Exemple concret d’estimation pour 500 mots générés
Concrètement, voici un exemple complet d’une estimation de coût d’utilisation de l’API OpenAI pour générer 500 mots. Prenons un modèle très utilisé qui est GPT-4o :
- Prompt = 200 mots = 260 jetons ;
- Réponse = 500 mots = 670 jetons ;
- Prix de GPT-4o = 2,50$/1M jetons pour le texte d’entrée et 10$/1M jetons pour le texte de sortie ;
- Coût : texte d’entrée de 260 jetons = 0,00065$ et texte de sortie de 670 jetons = 0,0067$ ;
- Coût total = 0,00735$/requête, 1000 requêtes = 7,35$, 10.000 requêtes = 73,5$ et 100.000 requêtes = 735$.
Optimiser les coûts : astuces et bonnes pratiques
Comme vous le voyez, un prix de requête pour environ 500 mots générés par l’IA est très faible, mais avec 100.000 requêtes, le prix peut atteindre jusqu’à 750 euros, ce qui peut être élevé pour certaines entreprises. Il faut alors réduire votre facture avec les meilleures stratégies, les voici :
- Choisir le bon modèle selon votre besoin: privilégiez les modèles abordables si vous êtes une PME ou un ETI ;
- Ingénierie des prompts efficaces: prompts courts, instructions claires, format précis et limiter la longueur de la réponse si possible ;
- Surveillance et analyse de l’utilisation: analyser les pics d’utilisation avec des outils d’OpenAI (tableau de bord, logs d’appel, consommation par modèle, historique) ;
- Utilisation de l’API Batch: qui regroupe plusieurs requêtes dans une seule opération pour réduire les frais, améliorer les performances et diminue le nombre d’appels d’API ;
- Mise en cache et réutilisation des résultats: si votre application envoie souvent les mêmes réponses, stockez-les avec votre base de données ou un cache memory locale.
Négociation de tarifs personnalisés pour les gros volumes
Pour les entreprises qui consomment des centaines de millions, voire des milliards de jetons par mois, OpenAI offre :
- Des réductions dégressives,
- Des contrats personnalisés,
- Des accès dédiés,
- Des quotas réservés,
- Des accords multi-annuels.
Ces négociations sont surtout accessibles via ChatGPT Enterprise ou directement via les équipes commerciales d’OpenAI. Une négociation réussie peut réduire une facture de 20 à 60 % selon les volumes, idéal pour les plateformes SaaS internationales avec beaucoup de demandes.
Grâce aux crédits gratuits OpenAI et à notre accompagnement expert, DigitalUnicorn vous aide à démarrer votre projet IA sans risque et à maximiser votre budget avec notre équipe compétente et expérimentée.
Questions fréquentes sur le coût de l’API OpenAI
L’utilisation de l’API est-elle incluse avec ChatGPT Plus ?
ChatGPT Plus donne accès aux modèles via l’interface ChatGPT, mais ne donne pas accès gratuitement à l’API.
Comment gérer et suivre mes dépenses API ?
Avec le dashbord d’OpenAI qui fournit : le suivi de dépense en temps réel, la fixation de limite mensuelle, l’analyse des appels à l’API, l’exportation des logs et bien d’autres.
Existe-t-il des remises pour les développeurs ou les startups ?
Dans certains cas, mais il faut remplir des conditions, comme des programmes universitaires, la consommation élevée de jetons par mois ou des partenariats avec des bundles de jetons. Les remises standards sont très rares.
La tarification change-t-elle fréquemment ?
Les frais sont ajustés à chaque sortie de nouveaux modèles, diminution des coûts d’infrastructure ou changement stratégique (baisse de client de GPT-4 par exemple).
Parlons donc de votre projet digital ! William, notre expert, est disponible pour en discuter. Appelez-le au 06 32 64 24 80 – Réponse en moins de 3 min, de 8h à 20h.










