Claude
Claude
Base44 a convaincu beaucoup d’équipes ces dernières années. Le principe est séduisant : décrire ce qu’on veut construire, laisser l’IA générer le code, et se retrouver avec une application fonctionnelle en quelques jours plutôt qu’en plusieurs mois. Pour lancer un MVP, tester une idée ou présenter un prototype à des investisseurs, ça marche très bien. Le problème, c’est ce qui se passe après. Une fois que l’application tourne, que les premiers utilisateurs arrivent et que les demandes d’évolution s’accumulent, les fissures commencent à apparaître. Des bugs difficiles à reproduire, des fonctionnalités nouvelles qui cassent des choses existantes, un backend qui rame sans raison évidente. Et là, la question qui revient systématiquement : est-ce qu’on peut sauver ce projet, ou est-ce qu’on recommence de zéro ?
La réponse honnête, c’est que ça dépend. Et pour le savoir, il faut commencer par regarder ce qu’on a vraiment sous le capot.
Pourquoi autant de projets Base44 finissent bloqués
Ce n’est pas une critique de l’outil en lui-même. Base44 fait ce pour quoi il a été conçu, et il le fait bien. Le problème vient du décalage entre les attentes du prototype et les exigences d’un produit en production.
Une phase de prototypage extrêmement rapide
La génération assistée par IA permet de produire des fonctionnalités en quelques heures. On décrit un comportement, on itère sur le résultat, et on obtient quelque chose de visuellement cohérent très vite. Pour un fondateur qui veut valider son concept, c’est une accélération réelle. On passe de l’idée à quelque chose de cliquable en un temps record, et ça change tout dans les premières phases d’un projet.
Le passage difficile entre prototype et application réelle
Le problème survient quand on essaie de faire évoluer ce prototype vers un vrai produit. L’architecture générée automatiquement n’a pas été pensée pour absorber une montée en charge, pour s’interconnecter avec des systèmes tiers ou pour accueillir des dizaines de nouvelles fonctionnalités. Chaque correctif ajouté sur une base fragile rend la structure un peu plus compliquée. À un moment, chaque modification devient un exercice de style dangereux.
Les limites qui apparaissent avec la croissance du projet
Les premiers signaux sont souvent des lenteurs inexpliquées. Les pages mettent plus longtemps à charger, les requêtes en base de données deviennent inefficaces, et certains comportements deviennent imprévisibles selon le contexte. Derrière ces symptômes visibles, il y a souvent une dette technique qui s’est accumulée silencieusement : des dépendances instables, des appels API redondants, une logique métier éparpillée entre plusieurs fichiers sans logique apparente.
Le problème du code qui fonctionne mais devient ingérable
C’est la situation la plus frustrante. L’application tourne, les utilisateurs s’en servent, mais personne n’ose y toucher de peur de tout casser. Le code généré par IA a tendance à produire des structures qui résolvent le problème immédiat sans anticiper les besoins futurs. Résultat : la logique métier se retrouve dispersée, les dépendances sont parfois contradictoires, et la structure d’ensemble devient difficile à lire même pour un développeur expérimenté qui prend le projet en main.
Première étape : réaliser un audit complet du projet existant
Avant de toucher quoi que ce soit, il faut comprendre ce qu’on a. Un audit technique sérieux prend du temps, mais c’est le seul moyen de prendre des décisions éclairées sur la suite.
Analyse de l’architecture globale
On commence par cartographier l’ensemble du système : le frontend, le backend, les API exposées ou consommées, et la structure de la base de données. L’objectif est d’identifier comment les différentes parties communiquent entre elles, où se trouvent les points de couplage fort, et quelles dépendances seraient difficiles à modifier sans provoquer des effets de bord.
Évaluation de la qualité du code
On regarde la lisibilité, la structure des fichiers, le taux de duplication, et la cohérence des conventions utilisées. Un code généré automatiquement est souvent fonctionnel mais rarement uniforme. On peut se retrouver avec plusieurs façons de faire la même chose dans des fichiers différents, ce qui rend la maintenance laborieuse.
Vérification des performances
Les temps de chargement, le nombre et la complexité des requêtes en base de données, les appels réseau inutiles : tout ça se mesure. Des outils de profiling permettent d’identifier les goulots d’étranglement réels plutôt que de corriger au hasard. Beaucoup de projets souffrent de requêtes non optimisées qui pourraient être résolues sans toucher à l’architecture.
Analyse de la sécurité
C’est souvent le point le plus négligé dans les projets générés rapidement. L’authentification est-elle correctement implémentée ? Les permissions sont-elles vérifiées côté serveur ou uniquement côté client ? Les données sensibles sont-elles correctement chiffrées ? Un projet utilisé en production par de vrais utilisateurs doit répondre à ces questions avant d’aller plus loin.
Identifier ce qui peut réellement être conservé
L’audit ne sert pas uniquement à dresser une liste de problèmes. Il permet aussi d’identifier ce qui est solide et réutilisable : des composants frontend déjà validés par les utilisateurs, une logique métier correctement encapsulée, un design qui fonctionne. Tout ça a de la valeur et mérite d’être conservé si la qualité est au rendez-vous.
Quand peut-on conserver le projet existant ?
Reprendre un projet sans le reconstruire entièrement est souvent possible, à condition que certaines conditions soient réunies.
Lorsque l’architecture reste exploitable
Si les grandes lignes de l’architecture sont cohérentes, que le frontend et le backend communiquent proprement, et que la base de données a une structure raisonnable, on peut travailler sur ce qui existe. Une architecture imparfaite mais cohérente est bien différente d’une architecture chaotique où chaque partie du code a sa propre logique.
Quand les fonctionnalités principales sont déjà stables
Si le cœur du produit fonctionne sans bugs majeurs et que les utilisateurs s’en servent sans se plaindre des fonctionnalités de base, il n’y a pas de raison de tout jeter. Les problèmes qui justifient une intervention concernent souvent les couches périphériques plutôt que le noyau fonctionnel.
Si le frontend est propre et réutilisable
Un frontend bien structuré, avec des composants réutilisables et une cohérence visuelle déjà validée, représente un travail significatif. Le remplacer sans raison technique valable serait une perte de temps et d’argent. Dans beaucoup de cas, on peut refactoriser uniquement le backend et la logique métier tout en conservant l’interface.
Les avantages d’une reprise partielle
Conserver ce qui fonctionne permet de gagner plusieurs semaines sur la mise en production d’une version stabilisée. Le budget s’en ressent positivement, et les utilisateurs existants ne sont pas perturbés par une refonte complète de ce qu’ils connaissent déjà.
Dans quels cas faut-il refactoriser le projet ?
La refactorisation est la voie du milieu. On ne repart pas de zéro, mais on restructure en profondeur certaines parties du code pour les rendre maintenables et évolutives.
Le code devient difficile à maintenir
Quand deux développeurs différents arrivent au même fichier et repartent sans comprendre ce qu’il fait, c’est un signe clair. Un code incompréhensible est un code dangereux, parce que chaque modification devient une prise de risque.
Les nouvelles fonctionnalités créent constamment des bugs
Si chaque ajout provoque des régressions dans des parties du code qui n’ont théoriquement rien à voir, c’est le signe d’un couplage trop fort entre les composants. La refactorisation vise précisément à découpler ce qui devrait être indépendant.
L’architecture backend manque de structure
Un backend généré par IA peut faire des choses étranges : mélanger la logique de présentation et la logique métier, gérer les accès à la base de données de façon incohérente, ou créer des dépendances circulaires. Ce type de problème se résout par une réorganisation progressive, pas forcément par une réécriture complète.
Comment refactoriser progressivement sans casser l’application?
La règle d’or est de ne jamais refactoriser et ajouter des fonctionnalités en même temps. On stabilise d’abord, on nettoie ensuite, on modularise progressivement. Chaque étape est couverte par des tests automatisés pour s’assurer qu’on n’a rien cassé. C’est plus lent qu’une réécriture brutale, mais beaucoup plus sûr pour un produit en production.
Quand faut-il envisager une reconstruction complète ?
Parfois, malgré la bonne volonté, le projet existant est trop abîmé pour être sauvé efficacement. Voici les signaux qui pointent vers une reconstruction complète.
Architecture totalement instable
Si l’audit révèle une architecture où les couches se mélangent sans logique, où les données transitent par des chemins incohérents, et où aucune partie du code ne peut être modifiée sans risquer d’en casser deux autres, continuer sur cette base coûte plus cher que repartir proprement.
Dette technique trop importante
La dette technique se mesure en heures de travail nécessaires pour remettre le code au niveau. Quand cette estimation dépasse le coût d’une reconstruction, le calcul est simple. Ce moment arrive plus vite qu’on ne le pense sur des projets générés automatiquement sans supervision technique.
Problèmes de sécurité critiques
Des failles de sécurité structurelles, c’est-à-dire qui tiennent à la façon dont l’application a été construite plutôt qu’à un bug isolé, ne se corrigent pas avec quelques patches. Elles nécessitent parfois de revoir l’architecture d’authentification, la gestion des sessions ou les droits d’accès depuis le début.
Base de données mal conçue
Une base de données avec des relations incohérentes, des tables surdimensionnées, des index manquants sur les colonnes critiques ou une absence totale de normalisation est difficile à corriger après coup. Migrer les données vers une structure propre pendant une reconstruction est souvent la seule option viable à long terme.
Comment reprendre un projet Base44 sans bloquer le produit existant?
La reprise d’un projet en production doit se faire sans interruption pour les utilisateurs. Ça demande de la méthode.
Prioriser les problèmes critiques
On commence par ce qui est urgent : les bugs bloquants, les failles de sécurité identifiées, les performances qui rendent l’application inutilisable sur mobile. Ces problèmes ont un impact direct sur la rétention utilisateur et ils doivent être traités avant toute chose.
Stabiliser avant d’ajouter de nouvelles fonctionnalités
C’est une décision difficile à prendre pour une équipe produit qui a des roadmaps à tenir, mais elle est incontournable. Ajouter des fonctionnalités sur une base instable revient à construire un étage supplémentaire sur des fondations fissurées. On aggrave le problème au lieu de le résoudre.
Reprendre le backend progressivement
On isole les parties du backend les plus problématiques et on les réécrit module par module, en maintenant la compatibilité avec le frontend existant. Cette approche permet de livrer des améliorations visibles régulièrement plutôt que de disparaître pendant trois mois pour une refonte invisible.
Préparer une architecture scalable
La reprise est aussi l’occasion de poser les bases d’une architecture évolutive : séparation claire des responsabilités, documentation minimale des décisions techniques, mise en place de tests automatisés sur les fonctionnalités critiques.
Faut-il migrer hors de Base44 ?
La question de la migration se pose naturellement quand les limites de l’outil deviennent contraignantes.
Les limites rencontrées sur certains projets
Base44 impose une certaine façon de faire les choses. Pour des projets qui sortent de ce cadre, qui nécessitent des intégrations complexes, des traitements lourds côté serveur ou une personnalisation poussée de l’infrastructure, ces contraintes deviennent des obstacles réels.
Quand une migration devient pertinente
Si l’application a vocation à croître significativement, à gérer des données sensibles soumises à des régulations strictes, ou à s’intégrer dans un écosystème technique existant, migrer vers une architecture maîtrisée de bout en bout est une décision qui se justifie.
Peut-on conserver une partie du projet existant ?
Oui, dans la plupart des cas. Le frontend peut souvent être conservé et adapté pour consommer une nouvelle API. La logique métier bien encapsulée peut être portée vers un nouveau backend. Et les données, même dans une base mal conçue, peuvent être migrées vers une structure plus propre avec les bons outils.
Combien coûte la reprise d’un projet développé avec Base44 ?
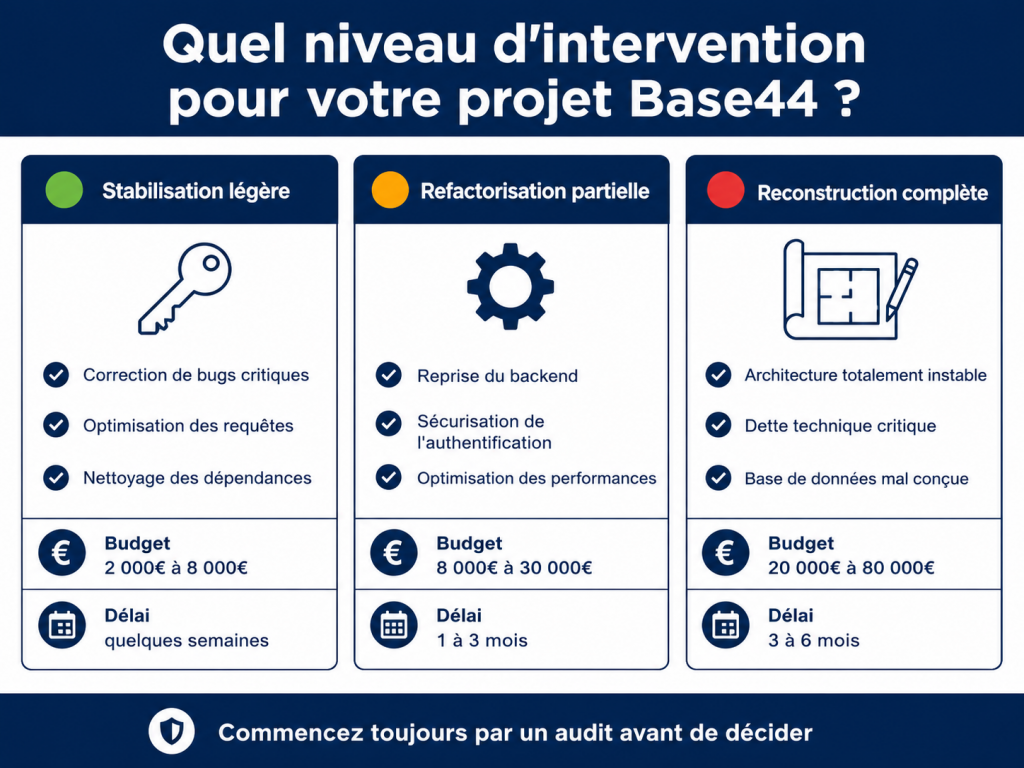
Les fourchettes sont larges parce que les situations le sont aussi. Voici les grandes catégories.
Cas 1 : stabilisation légère
Correction de bugs critiques, optimisation des requêtes les plus lentes, nettoyage des dépendances inutilisées. Ce type d’intervention se situe généralement entre 2 000€ et 8 000€ et peut se faire en quelques semaines sans interrompre le service.
Cas 2 : refactorisation partielle
Reprise du backend, sécurisation de l’authentification, optimisation des performances, modularisation du code. On parle ici d’une intervention entre 8 000€ et 30 000€ selon la taille du projet, étalée sur un à trois mois.
Cas 3 : reconstruction complète
Quand la dette technique est trop lourde, une reconstruction complète avec migration des données représente un investissement entre 20 000€ et 80 000€ ou plus selon la complexité fonctionnelle. C’est significatif, mais c’est souvent moins coûteux que de continuer à corriger un projet structurellement fragile pendant des années.
Les facteurs qui influencent réellement le budget
La qualité du code existant, le nombre de fonctionnalités à reprendre ou à reconstruire, l’état de la base de données et la complexité des règles métier sont les quatre variables qui pèsent le plus dans l’estimation. Un projet de taille modeste avec un code chaotique peut coûter plus cher à reprendre qu’un projet plus grand mais mieux structuré.
Comment notre agence reprend un projet Base44 existant?
Notre approche repose sur un principe simple : ne rien casser avant d’avoir compris ce qui fonctionne.
Audit technique complet
On commence systématiquement par une analyse complète du code existant avant de proposer quoi que ce soit. Cet audit couvre l’architecture, les performances, la sécurité et la qualité du code. C’est la base de toute décision technique sérieuse.
Plan de reprise détaillé
À partir de l’audit, on établit un plan priorisé : ce qu’on corrige en premier, ce qu’on refactorise progressivement, et ce qu’on reconstruit si nécessaire. Chaque décision est argumentée et discutée avec vous avant d’être mise en oeuvre.
Nettoyage et stabilisation du code
On commence par rendre le projet stable et prévisible avant d’envisager des évolutions. Ça passe par la suppression du code mort, la correction des bugs récurrents et la mise en place de tests sur les fonctionnalités critiques.
Refonte progressive si nécessaire
Quand une partie du projet doit être refaite, on le fait module par module pour minimiser les risques. L’application reste en ligne pendant toute la durée des travaux.
Déploiement et accompagnement
On assure le déploiement des améliorations et on reste disponibles pour les ajustements qui suivent la mise en production. Un projet repris proprement demande quelques semaines de stabilisation avant d’être pleinement fiable.
Les erreurs à éviter lors de la reprise d’un projet Base44
Tout supprimer trop rapidement
L’impulsion de tout jeter et de repartir de zéro est compréhensible quand on tombe sur un code difficile à lire. Mais elle fait perdre du temps et de l’argent sur ce qui fonctionnait déjà bien. L’audit est là pour éviter cette réaction à chaud.
Ajouter des fonctionnalités sur une base instable
C’est l’erreur la plus fréquente. L’équipe produit pousse pour avancer, et on cède à la tentation d’ajouter des choses avant d’avoir stabilisé ce qui existe. Le résultat est invariablement une accumulation de bugs plus difficiles à corriger.
Négliger la sécurité
Les problèmes de sécurité sont rarement visibles par les utilisateurs, ce qui les rend faciles à remettre à plus tard. C’est une erreur qui peut avoir des conséquences sérieuses, notamment sur des projets qui gèrent des données personnelles ou financières.
Vouloir aller trop vite avant stabilisation
La stabilisation prend le temps qu’elle prend. Accélérer cette phase en sautant des étapes, en ne testant pas suffisamment ou en faisant plusieurs choses en même temps multiplie les risques d’incidents en production.
Un projet Base44 bloqué n’est pas forcément à refaire
La plupart des projets qui arrivent chez nous dans un état difficile peuvent être sauvés, au moins partiellement. La clé, c’est de ne jamais décider avant d’avoir audité. Un projet qui semble catastrophique peut révéler un frontend solide et une logique métier correctement implémentée sous une couche de code désorganisé. À l’inverse, un projet qui tourne bien en surface peut cacher une architecture qui rendra impossible toute évolution sérieuse dans six mois.
L’approche progressive est presque toujours meilleure que la table rase. Elle préserve ce qui a de la valeur, elle réduit les coûts, et elle permet de livrer des améliorations concrètes pendant la phase de reprise plutôt que de bloquer le produit le temps d’une reconstruction. Si votre projet Base44 vous donne du fil à retordre, commencez par un audit technique : c’est rapide, ça ne coûte pas grand chose, et ça change radicalement la clarté des décisions à prendre. Contactez-nous pour un audit gratuit de votre projet existant et une estimation de reprise adaptée à votre situation réelle.
Vous avez un projet Base44 à stabiliser, refactoriser ou reprendre en main ? William, notre expert en transformation digitale, est disponible dès maintenant. Contactez-le au 06 32 64 24 80 — réponse en moins de 3 minutes, de 8h à 20h. Vous pouvez aussi nous contacter par email à contact@digitalunicorn.fr.